ChatGPT and LCSHs
When assigning descriptive values to metadata elements, vocabulary and syntax is of the utmost importance. Whenever we label a metadata element subject we should realize that one person’s “World War II” is another’s “WW II.” If the value for the subject element were “World War II” for one resource and “WW II” for another, we’d be able to safely assume that both were, generally speaking, about World War II. Further still, “WWII,” “World War 2,” “WW 2” and “WW2” are probably also descriptive enough for us to determine that any resources with these values for the subject element are also about World War II. All six hypothetical resources have different values for subject, but because we’re able to process their meaning in our heads without thinking twice, we know that in actuality they all represent the same thing: the Second World War
But from an information science perspective, all seven of these values are different. Databases, catalogs, search algorithms—just as (35.95 ≠ 36.00), (“WW2” ≠ “WWII”). We know that such a distinction is pretty much pedantic, but computers are proudly pedantic. You will never be able to convince one that a number, which isn’t another number, is, actually, that other number. Similarly, it can only see “WW2” and “WWII” as two different values.
The potential for the presence of technical inconsistencies of this kind in metadata records presents a problem. Two separate books on World War II might remain bibliographically separated if the values given to the subject element aren’t identical. To better manage this sort of problem, we can ensure that the subject element adheres to a controlled vocabulary. Whenever World War 2 shows up in the subject element, it should equal “World War II” exactly. We can standardize and establish these rules for humans to follow, and we can even tell computers to sort through existing metadata to find instances of vocabulary or syntactical inconsistency and change the values to preferred formats.
In terms of a subject element for bibliographic metadata records, a controlled vocabulary is crucial. By a wide margin, the best available controlled vocabulary for this kind of metadata is the Library of Congress Subject Headings (LCSHs). Cataloging specialists at the Library of Congress create roughly 5,000 new subject headings annually and release them to the public. If you look on the copyright page (or verso) of any book, you’ll find the LCSHs for that book. The LOC analyzes the content of a book prior to its publication and prints the LCSHs on this page for bibliographic and reference purposes.
Ostensibly, it takes more than one person to arrive at an appropriate list of LCSHs for a given work. I’m thinking that for each book at least a handful have to do some of the read-y grunt work, select subject headings, compare their work with each other, and then decide as a group which will make the cut. Or something. Regardless, analyzing content for this purpose is not easy and is time consuming and is probably best achieved as a group.
But I’ve been wondering lately—how good would ChatGPT be at it?
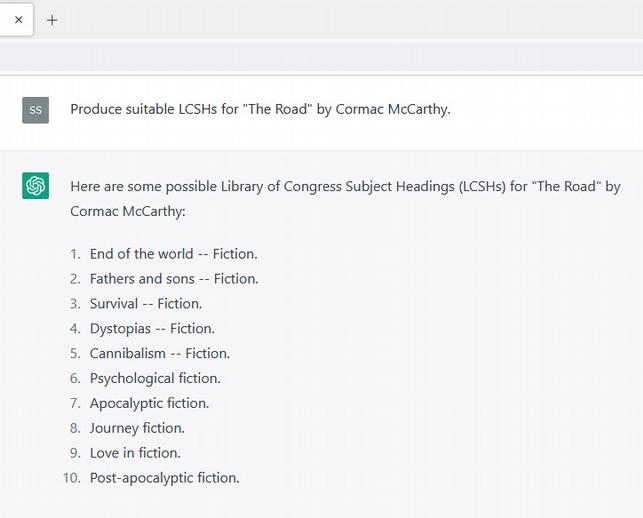
Vs. the actual LCSHs from a copy of The Road:
- Fathers and sons—Fiction.
- Voyages and travels—United States—Fiction.
- Regression (Civilization)—Fiction.
- Survival skills—Fiction.
ChatGPT enjoys the luxury of ten LCSHs for some reason. In fact, I’m not sure how exactly the LOC governs the number of LCSHs to be included, but four seems a little sparse. “Apocalyptic fiction,” as chosen by ChatGPT, seems like a fitting addition (and the book isn’t about cannibalism, per se, but it’s definitely got some in there). I think the fact that the official LCSHs are limited to four yet are deceptively concise means a lot goes into landing on an appropriate list. ChatGPT does not reproduce the same list consistently, implying to me that there is some educated guessing at work here. Still, the general suitability and legitimacy of what it produces is unavoidable—it’s clear that ChatGPT could be utilized to some extent by library and information science professionals to productive and useful ends.
Tags: chatgpt, lcsh
← Back home